Findex Encrypted Search API
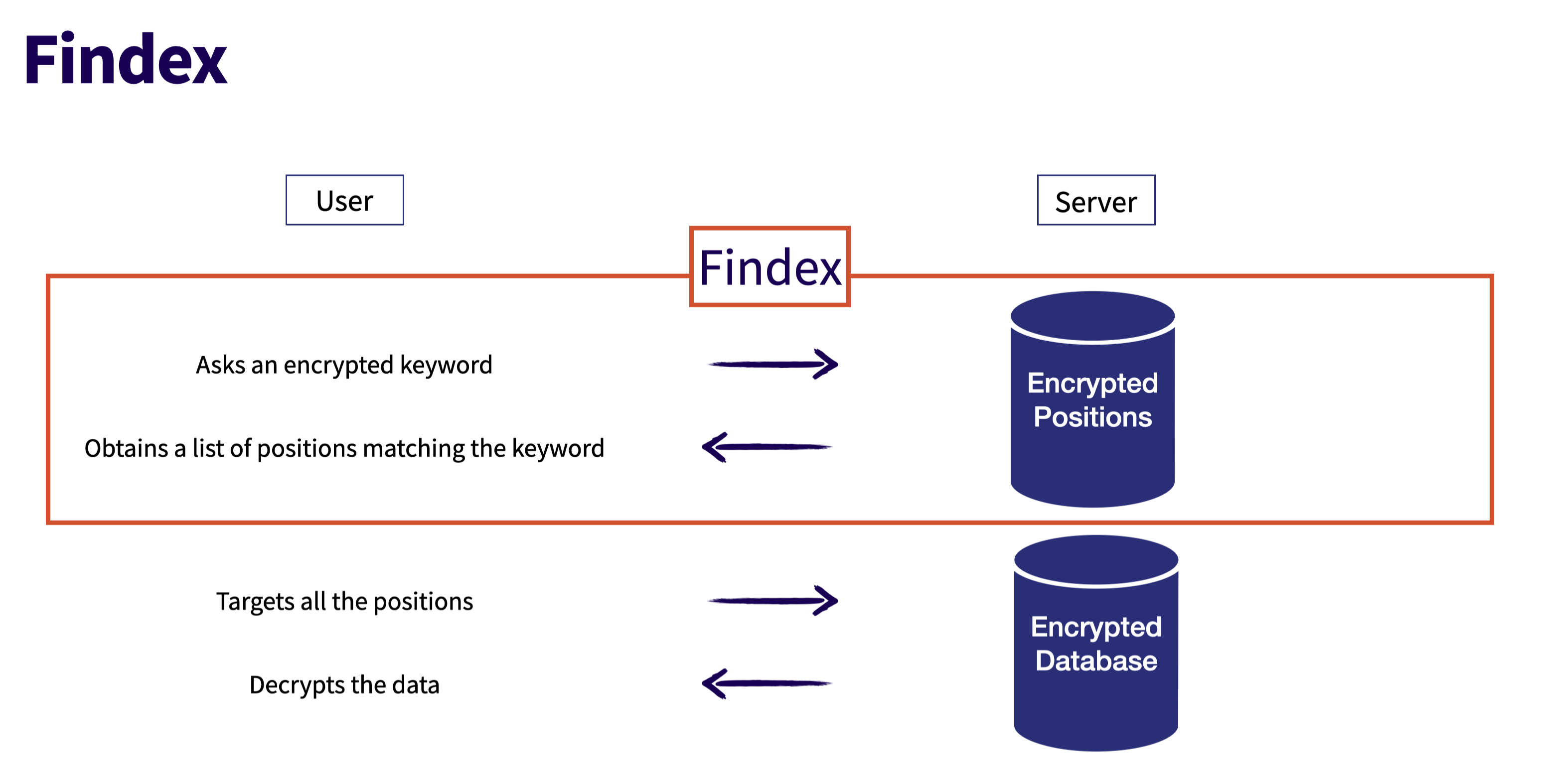
Cosmian Findex is a Searchable Encryption scheme that allows the building of encrypted indexes. One can efficiently search these encrypted indexes using encrypted queries and receive encrypted responses.
Since the environment cannot learn anything about the content of the index, the queries, or the responses, one can use Zero-Trust environments, such as the public cloud, to store the indexes.
Implementations and quick start¶
The Findex core cryptographic library is open-source and written in Rust. For cryptographic documentation and implementation details, check the Findex Github repository.
Unless low-level programming in Rust, implementers should use Findex through the various cloudproof_xxx user libraries, where xxx is either Javascript, Java, Python, or Flutter. All these libraries are open-source and available on Github
The user libraries all contain extensive tests, and it is highly recommended to start by hacking those tests.
Setup¶
The library is published on npm: simply install the library in your package.json
The library contains web assembly for cryptographic speed
You need Java 8+ and Maven version 3+ The cloudproof_java library is deployed on Maven central. Add the library to your POM
The version 4.0.0 is available on PyPI:
Import statement:
The library is published on pub.dev as a Dart library: https://pub.dev/packages/cloudproof. To install it:
The library contains cryptographic native libraries called through FFI functions.
Searching the encrypted index¶
The typical user search workflow is as follows:
-
Using a client library (java, python, js, ios, android, etc.), the user supplies a searched keyword and encrypts it using a secret key.
-
The client library issues two encrypted requests to the key-value store storing the index (the key-value store can be any store of your choice - see below)
-
The client library decrypts the response, typically the locations in the main DB where the keyword is found.
The user will then query the main database for the given records, encrypted with application level encryption, and decrypt what their private key allows.
Updating and compacting the index¶
In addition to the search functionality, Findex proposes an upsert (i.e. update or insert) function and an index compacting function.
The upsert function allows concurrent updating of the index while in use. Update conflicts are resolved using a mechanism based on retries. See the callback to upsert Table Entry lines for details. The Sqlite and Redis implementations available in the various languages provide implementation examples.
The index compacting function provides two essential functionalities:
- it reduces the index size by removing entries pointing to locations that no longer exist in the main database.
- it rotates ciphertexts, and thus stops potential statistical attacks by an attacker listening to encrypted queries on the encrypted indexes.
Understanding Findex: keywords, indexed values, and search graphs¶
Findex maintains a key -> value relationship between Keyword -> set of IndexedValue.
The Keyword may be any arbitrary array of bytes.
The IndexedValue may be:
- a
Location(such as a DB record uid, a file name, or an arbitrary sequence of bytes) - or another
Keyword(for instance, “Bob” may point to “Robert”, so querying “Bob” will also return the Locations for “Robert”).
When performing a search for a given Keyword, Findex will retrieve the set of all corresponding IndexedValues. If the IndexedValue is a Location, it will be returned; if the value is another Keyword, Findex “walks the graph” by performing a search on that new Keyword and returning the Locations along the way.
To build the index, we must provide one or more maps of IndexedValues to Keywords.
The first step is to create a map of all the Keywords that need to be indexed for a particular Location. Say, we want to index the following employee record first name and last name of a database where the records a uniquely identified by the employee ID.
| Employee ID | Last Name | First Name | Department |
|---|---|---|---|
| ab345 | Martin | David | AE42 |
For case insensitive search, The first step will be to build the map with the entry:
Now, say we also want to retrieve Martin when the user performs a last name search on mar. To do so, we add to the map, the entries for the graph of keywords that lead from lastname=mar to lastname=martin
Keyword ("last_name=mart") -> {"last_name=mar"}
Keyword ("last_name=marti") -> {"last_name=mart"}
Keyword ("last_name=martin") -> {"last_name=marti"}
When searching for lastname=mar, Findex will find the next keyword lastname=mart, search for it, find the next keyword lastname=marti, search for it, find the next keyword lastname=martin, search for it, find the location ab345 for Martin then return it.
Building the intermediate graph nodes mart and marti builds a full starts-with text search functionality. Say we build similar graphs for Marthe (last_name=marthe) and Marie (last_name=marie), a search query on the last name for
marwill retrieve the locations forMartin,Marthe, andMariemart=>Martin,Marthemarti=>Martin
Please note that it suffices to reverse the keywords and generate similar graphs, to implement a full ends-with text search functionality.
The CloudProof Python library provides a helper function to generate an auto-completion graph.
Implementing the Index tables callbacks¶
The Findex library abstracts the calls to the tables hosting the indexes.
The developer is expected to provide the database’s backend, typically a fast key/value store, and implement the necessary code in the callbacks used by Findex.
Findex uses two tables: the Entry table and the Chain table. Both have two columns: uid and value.
Depending on the role of the client code using Findex, only certain callbacks need to be implemented. To perform:
- searches: the two callbacks to fetch Entry Table lines and Chain Table lines, and optionally, the progress callback.
- updates: the callback to fetch Entry Table Lines and the 2 callbacks to upsert Entry Table lines and upsert Chain Table lines.
- compacting: the 3 callbacks to fetch all Entry Table UIDs, the Entry Table lines, and the Chain Table lines, as well as, the callback to update the table lines and the callback to determine the locations that no longer exist in the main database.
The type UidsAnValues represents a list of (uid, value) tuple, i.e., a line, in the Entry or Chain table. Its definition is
Another useful type is UidsAndValuesToUpsert, which is used during upsert to set a new value only if the old value match inside the database.
With regards to the Findex callbacks, the developer should provide instantiations of the following function types
The library implements callbacks for some databases in the tests:
- Better SQLite 3 callbacks
- In memory callbacks
- Redis callbacks
- Other in memory callbacks in the VueJS and ReactJS examples
You can start by using callbacksExamplesBetterSqlite3() or callbacksExamplesInMemory() to try the library but we do not officially support these. You are encouraged to build your own callbacks for your database.
The developer should provide the implementation of a series of callbacks declared in the interface Database. The easiest way to do this is to hack the existing implementations provided for Sqlite and Redis
The objects used in the callbacks, Uid32, EntryTableValue, ChainTableValue are straight wrappers of byte arrays. Please note that Uid32 has a fixed length of 32 bytes.
The library implements callbacks for some databases in the tests:
The developer should provide the implementation of 4 callbacks required by the functions search and upsert from the class Findex.
A sample implementation of these callbacks for Sqlite is available in the class SqLite
The library implements callbacks for some databases in the tests:
Depending on its needs, the developer should provide the implementation of one or more abstract classes: FindexUpsert, FindexSearch or FindexCompact declared in CloudProof Python.
For example if one needs to use Upsert and Search for SQLite database, the class should implement the following methods:
Please see the implementations inside CloudProof Python for callbacks example with SQLite.
Generating the Findex key¶
Findex uses a single symmetric 128 bit key to upsert and search. Encryption is performed using AES 128 GCM.
To generate 16 random bytes locally, use the randomBytes generator from 'crypto'
To generate symmetric keys in a Cosmian KMS server, find the server address and - unless you run in dev mode - an API Key to authenticate to the server.
To generate 16 random bytes use the SecureRandom cryptographically secure random number generator (CSRNG)
Indexing: inserting and updating keywords¶
First prepare a map of indexed value to keywords, then use the Findex upsert function to upsert (update or insert) entries in the index.
Map of Indexed Values to Keywords¶
To perform insertions or updates (a.k.a upserts), supply an array of IndexedEntry.
This structure maps an IndexedValue to a list of Keywords. Its definition is
Depending on your database ID type, you can use several Location helpers:
- If your IDs are strings use
Location.fromString("xxx")during upsert andlocation.toString()during the search - If your IDs are numbers use
Location.fromNumber(42)during upsert andlocation.toNumber()during search - If your IDs are UUIDv4 use
Location.fromUuid("fa942211-a090-4cc2-bd6c-a4da5b164806")during upsert andlocation.toUuid()during search - If your IDs are something else use
new Location(idEncodedInUint8Array)during upsert andlocation.bytesduring the search
To upsert data, one must provide a Map<IndexedValue, Set<Keyword>> map.
The class IndexedValue can be constructed using either a Location or a NextKeyword as appropriate.
IndexedValue indexedValue = new IndexedValue(new Location("ab345"));
assertTrue(indexedValue.isLocation());
indexedValue.getLocation(); // ==> returns the Location or throws if not a Location
//
IndexedValue indexedValue = new IndexedValue(new NextKeyword("marti"));
assertTrue(indexedValue.isWord());
indexedValue.getWord(); // ==> returns the NextKeyword or throws if not a NextKeyword
To perform insertions or updates (a.k.a upserts), supply a map: Map<IndexedValue, List<Keyword>>.
This structure maps an IndexedValue to a list of Keywords.
An IndexedValue can be either a Location or a Keyword.
from cloudproof_py.findex import Location, Keyword
# a location is usually the id of the corresponding entry in the database
# create a Location from a string, bytes or int
location = Location.from_string("Bob's database index")
location = Location.from_bytes(b"Bob's database index")
location = Location.from_int(1)
# create a Keyword from a string, bytes or int
keyword = Keyword.from_string("Bob")
keyword = Keyword.from_bytes(b"Bob")
keyword = Keyword.from_int(10)
Labeling: salting the encryption¶
When indexing, the encryption uses an arbitrarily chosen public label; this label may represent anything, such as a period, e.g., “Q1 2022”. It should be changed when the index is compacted or recreated. Changing it regularly significantly increases the difficulty of performing statistical attacks.
Upserting the entries¶
After having:
- Implemented the callbacks (see implementing the callbacks)
- Generated the keys (see generating Findex key)
- the label is set for this version of the index (see Labeling)
- the entries are generated,
call the upsert function :
const { upsert } = await Findex();
await upsert(
[
{
indexedValue: Location.fromNumber(1),
keywords: ["John", "Doe"],
},
{
indexedValue: Location.fromNumber(2),
keywords: ["Jane", "Doe"],
},
],
masterKey,
label,
async (uids) => {
// Return the entry table
},
async (uidsAndValuesOldAndNew) => {
// Save the new uidsAndValues inside the entry table (only if the old value is the same as the one stored in the database)
// return the rejected uids with the values inside the database, the callback will be called again with the updated value
},
async (uidsAndValues) => {
// Save the new uidsAndvalues inside the chain table
},
);
To upsert use the Findex.upsert function
Example:
Querying the index¶
Querying the index is performed using the search function.
const { search } = await Findex()
const results = await search(
["Doe"],
masterKey,
label,
async (uids) => {
// Fetch entry table
},
async (uids) => {
// Fetch chain table
},
)
const locations = results.locations()
// locations will contain `locations[0].toNumber() === 1` and `locations[1].toNumber() === 2` (or in another order)
// You can also fetch the locations only for one keyword if you sent multiple keywords during search
const locationsForDoe = results.get("Doe")
The progress callback sends back the IndexedValues found as the search algorithm walks the index graph. It is a callback function with a signature
protected abstract boolean searchProgress(List<IndexedValue> indexedValues) throws CloudproofException;
Assuming the keywords graph car -> care -> caret, and a search for anything starting with car, the progress callback will be called 3 times, returning locations found for car, then care, and finally caret.
Returning false in the callback will immediately stop the algorithm from further walking the graph.
To perform a search, call the Findex.search method. Like searchProgress, the fetchEntries and fetChains callbacks must also be implemented.
The maxDepth parameter sets the maximum depth of the graph that will be traversed when Findex walks the graph of NextKeywords.
Assuming the 2 callbacks fetchEntries and fetchChains are implemented, the search function can now be called.
static Future<Map<Keyword, List<IndexedValue>>> search(
Uint8List k,
Uint8List label,
List<Keyword> keywords,
FetchEntryTableCallback fetchEntries,
FetchChainTableCallback fetchChains,
{int outputSizeInBytes = defaultOutputSizeInBytes}) async {
...
}
for example:
The search function of Findex returns the Locations found for a list of Keywords. Here is the search method interface:
Example:
Advanced search¶
When using aliases in your indexes, the search is recursive. At each step of the recursion, one can get the latest results by providing a progress callback to the search function.
This callback can also be used to stop the recursion when the desired results has been found by returning false.
static int progress(Map<Keyword, List<IndexedValue>> progressResults) {
// new results in `progressResults`
return 1;
}
static int progressCallback(
Pointer<UnsignedChar> uidsListPointer,
int uidsListLength,
) {
return Findex.wrapProgressCallback(
progress,
uidsListPointer,
uidsListLength,
);
}
await Findex.searchWithProgress(
masterKey,
label,
keywords,
Pointer.fromFunction(
fetchEntriesCallback,
errorCodeInCaseOfCallbackException,
),
Pointer.fromFunction(
fetchChainsCallback,
errorCodeInCaseOfCallbackException,
),
Pointer.fromFunction(
progressCallback,
errorCodeInCaseOfCallbackException,
));
}
Compacting the Index¶
Compacting requires the full implementation of all the callbacks.
Compacting should be performed by a single client on a single thread on a machine with several gigabytes of available memory.
To make statistical attacks hard to conduct, the compact algorithm completely re-encrypts the Entry Table. Since the encryption is deterministic, either the key (which is secret) or the label (which is public), or both, should change.
Changing the label has the advantage that, since it is public, it can be easily communicated via public channels to users.
Changing the key has the disadvantage that, since it is private, it must be communicated to users on secure channels. However, rotating the key rather than the label will allow “dropping” users: those who do not know the new key, will no longer be able to use the index.
The Chain Table, which is the largest table, does not need to be fully re-encrypted on every compact operation. A parameter of the compact function controls the number of times the compact operation must be run so that the probability of having re-encrypted the whole chain table is large. This parameter should be seen as a compromise between compaction speed and size efficiency; obviously, re-encrypting a larger portion also adds to the security.
The compacting operations can be performed in 2 ways.
Cold compacting¶
Users should stop using the index while compacting is in progress.
The updateTables callback should implement the following algorithm:
- remove all the Index Entry Table
- add new_encrypted_entry_table_items to the Index Entry Table
- remove removed_chain_table_uids from the Index Chain Table
- add new_encrypted_chain_table_items to the Index Chain Table
Hot compacting¶
Users can still use the index while compacting is in progress but some search results may be incomplete and the process takes longer.
The updateTables callback should implement the following algorithm:
- save all current UIDs of the current Index Entry Table
- add new_encrypted_entry_table_items to the Index Entry Table
- add new_encrypted_chain_table_items to the Index Chain Table
- publish the new label to users
- remove old lines from the Index Entry Table (using the saved UIDs in 1.)
- remove removed_chain_table_uids from the Index Chain Table